
Effective Communication with Generative AI
We certainly know that Generative AI is a groundbreaking field that has evolved rapidly, offering incredible potential for creativity and problem-solving. Communicating effectively with these models is critical and involves mastering the art of prompt engineering.
At the core of interacting with generative AI is the concept of prompts and completions. A prompt is the input that is provided to the model, guiding it to generate relevant and coherent outputs. Those outputs returning from the LLM are called completions, i.e., the LLM effectively says, “I will use your prompt starting point and complete a string of words based on the most probable ones that I have learned”.
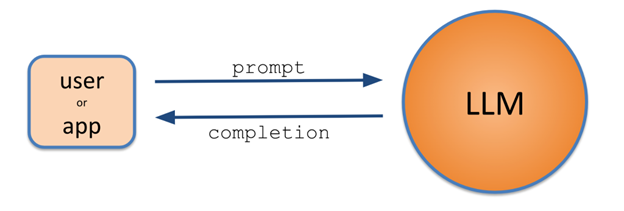
Understanding the relationship between prompts and completions is key to getting an LLM to generate the desired result. Crafting prompts with precision is vital for obtaining desired and meaningful completions.